Transformer架构正在重塑AI产品的思维逻辑,但其工作原理往往被复杂公式所掩盖。本文将用职场场景隐喻拆解AI引擎的核心机制:从RNN的死记硬背到Transformer的全局视野,揭秘编码器的全景复盘与解码器的蒙眼推理,剖析QKV机制的侦探游戏与Softmax的残酷淘汰,带你穿透技术迷雾重新认知这台万亿级推理机器。

AI不是神。AI也不是魔法。
作为产品经理,我们经常被这一波技术浪潮拍得晕头转向。我也曾陷入焦虑:那些满屏的矩阵、公式、论文,到底在说什么?
直到我看透了它的本质。今天,我想邀请你把那些复杂的数学公式都扔到一边。我们将用最直观的“职场直觉”,拆解这台价值万亿的机器。
你会发现,Transformer的运作逻辑,其实和人类的思维方式一模一样。
一、告别那个“死记硬背”的笨学生(RNN)
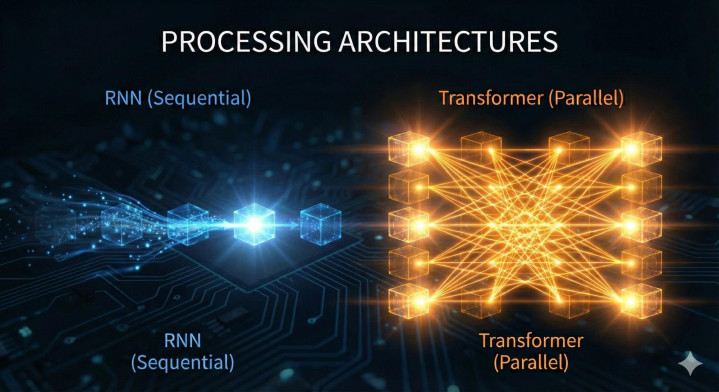
在Transformer出现之前,AI界的“学霸”叫RNN。它很努力,但它有个致命的毛病:它只能死记硬背。
RNN就像一个患有短期失忆症的小学生。老师让他朗读课文,他必须一个字、一个字地读。更糟糕的是,当他读到第100页时,他已经完全忘记第1页的主角叫什么名字了。
这就是为什么以前的AI总是前言不搭后语。它没有大局观。
Transformer的出现,彻底颠覆了这一切。它抛弃了“逐字阅读”。它拥有了“上帝视角”。它能并行计算,一眼把整本书看完,瞬间理解所有人物错综复杂的关系。
但这台机器分裂成了两种截然不同的性格:编码器(Encoder)和解码器(Decoder)。
二、编码器(Encoder)——全知全能的“复盘者”
Transformer的第一半心脏,叫Encoder。它的任务是极致的理解。
它的工作模式,就像我们在做项目“复盘”。
当我们复盘一个项目时,整个时间轴是完全展开的。我们既知道开头的“立项”,也知道结尾的“上线”。我们拥有一切信息。Encoder就是在做复盘。
想象一下这句话:
“苹果发布了新手机,而我正在吃一个苹果。”
因为是全盘复盘,Encoder拥有“上帝视角”(双向注意力):
1)全局扫描:当它分析第一个“苹果”时,它能同时看到这句话里的所有线索。
2)建立连接:
它在句中发现了“手机”,瞬间判定第一个苹果是科技公司。
它在句中发现了“吃”,瞬间判定第二个苹果是水果。
它不需要按时间顺序猜。所有的线索,无论是过去的还是未来的,在它眼中是透明的。这就是为什么像BERT这种基于Encoder的模型,阅读理解能力地表最强。因为它“作弊”了——它看穿了全局。
三、解码器(Decoder)——蒙眼挑战的“即兴演讲者”
好了,关键的问题来了。既然Transformer能一眼看穿全局,为什么ChatGPT还要一个字一个字地往外蹦?
因为,“复盘”和“即兴演讲”完全是两码事。
这就涉及到了Transformer的第二半心脏——解码器(Decoder)。
在Decoder的世界里,规则变了:
Encoder(复盘):Q(探照灯)是全向的。它想看前文还是后文都可以,因为它拥有所有数据。
Decoder(即兴演讲):Q(探照灯)是单向的。它只能回头看已知的历史,绝对无法看到未知的未来。
为什么?因为演讲存在“时间悖论”。当你正在即兴演讲说出“今天”这两个字的时候,“明天”的内容还没发生呢!你不可能去注意一个不存在的东西。
为了模拟这种“即兴演讲”的高压环境,我们必须给Decoder戴上一副眼罩——Mask(掩码)。
Mask的铁律:禁止偷看剧透。我们在训练时,会把填空位置后面的所有字强行涂黑。这就像在训练一个绝地武士。我们蒙住他的双眼,让他无法依赖视觉(直接抄答案),只能被逼着去感受周围的逻辑气场。

四、QKV机制——在黑暗中“侦探破案”
既然看不见未来,Decoder怎么知道下一个字该写什么?这就到了最精彩的“QKV侦探游戏”。
让我们回到那个经典的推理现场:
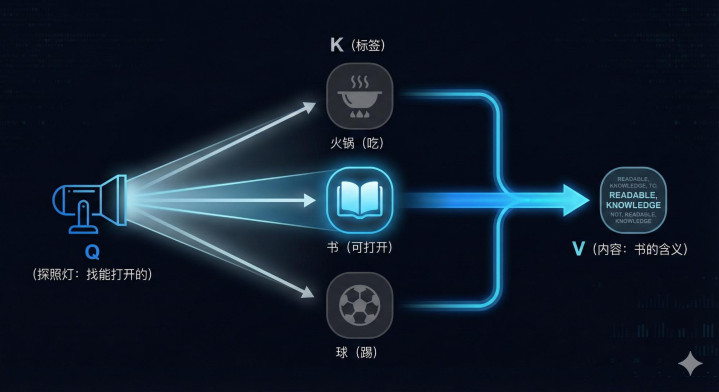
上文(即兴演讲已完成的历史):“今天早上,我买了一本书。下午,我去踢了球,累得半死。晚上,我和朋友吃了一顿火锅。回到家躺在床上,我终于打开了…”
AI当前要生成的词:____(它还不知道是“书”)
Decoder内部的QKV是这样运作的:
第一步:发出信号(Query-探照灯)当模型生成到“打开”这个动作时,它的Q发出强烈的信号:“我在找一个能被‘打开’的历史线索。”
第二步:全场扫描(Key–身份标签)探照灯只能向回扫射(因为未来被Mask挡住了),它照到了以前发生过的所有名词:
它照到了“火锅”。火锅的K(标签)显示:、。探照灯摇摇头:不对,火锅是用来吃的,不是用来打开的。排除。
它照到了“球”。球的K(标签)显示:、。探照灯摇摇头:不对,球是用来踢的。排除。
最后,它照到了“书”。书的K(标签)显示:、、。Bingo!逻辑匹配!
第三步:提取内容(Value)Attention机制瞬间建立了一条高速通道,把“书”的含义(Value)抓取了过来。
于是,AI顺理成章地写下:“我终于打开了它(书)”。
这就是为什么它不能看未来,却能写出未来。它不是在瞎猜,它是在用单向注意力,基于历史逻辑,一步步推演出未来。
五、深度之谜——摩天大楼的地基
现在逻辑通了:Encoder负责全知复盘,Decoder负责即兴演讲。但这就够了吗?不够。
如果只做一层神经网络,AI只能学会简单的“连连看”(比如看到“打开”,就找“名词”)。但要学会复杂的逻辑、幽默、反讽,甚至是写代码,AI的“脑回路”必须足够深。“浅”意味着简单直接,“深”才意味着智慧。所以,现代的Transformer模型往往堆叠了几百层甚至上千层。
但凡是做过管理的人都知道:层级多了,指令就会传走样。
Transformer用了两招天才般的“职场管理术”,保证了这座摩天大楼稳如泰山。
残差连接(ResidualConnection):不忘初心
它用了一个极简的公式:Output=Process(x)+x
翻译成人话:
Process(x):是你这一层新学到的逻辑。
x:是上一层传下来的原始信息。
x:意思是“保留原话”。
普通的网络,层数多了会出现梯度消失(即“脑瘫”风险)。而残差连接强制要求:无论你这一层怎么瞎折腾,最后输出时,必须把上一层的原始信息加上。这就像老板对员工说:“你可以在我的方案上修改,但必须把我的原稿作为附件发回来。”
层归一化(LayerNormalization):统一格式
在一个巨大的团队里,有的神经元数值会飙升到1000(过度兴奋),有的则低沉到0.001。这种数值剧烈波动会让整个系统崩溃。
LayerNorm就像是公司的“标准化排版”。不管你是天才还是庸才,每经过一层,它都会强制把大家的数据拉回到一个标准的起跑线。它保证了模型在长达数月的训练中,情绪稳定,不会“炸”掉。
六、Softmax——残酷的“末位淘汰赛”
好了,侦探破案结束,大楼地基也稳了。现在,模型走到了最后一步。它要交卷了。
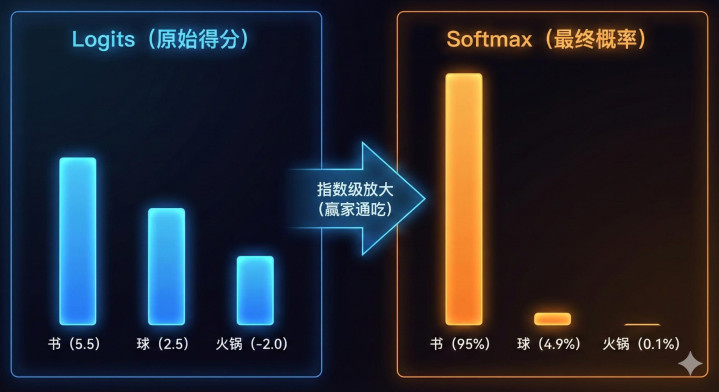
面对填空题:“我打开了____”,解码器输出的不是一个词,而是一组Logits(原始得分):
“书”的得分:5.5(稍微领先)
“球”的得分:2.5(稍微落后)
“火锅”的得分:-2.0(完全离谱)
注意看,这时候“书”和“球”的原始分差只有3分。这些分数人类看不懂,机器也不好选。于是,Softmax登场了。
很多教材说它是“归一化”,太晦涩。你应该把它看作是一场“赢家通吃”的投票放大器。它利用指数运算($e^x$),强行把微小的分差无限拉大,并转换成概率。
Softmax计算后,奇迹发生了:
5.5分->95%(书)
2.5分->4.9%(球)
-2.0分->0.1%(火锅)
看到Softmax的威力了吗?原本只有3分的差距,在指数的作用下,瞬间变成了一场95%对5%的一边倒屠杀。它极其残酷。它会放大第一名的优势,把微弱的得分差距,变成绝对的概率统治。
此时,Temperature(温度)参数决定了最后的结局:
调低温度:你逼迫AI只能选95%的那个词。它变成了严谨的会计。
调高温度:你允许AI偶尔去选那个4.9%的词。它变成了疯癫的诗人。
七、超越语言——AI界的“六边形战士”
读到这里,你可能以为Transformer只是一个聊天机器人。你错了。
Transformer的本质,是处理“序列”的关系。而在数学家眼里,万物皆序列。
这就是为什么Transformer正在走出文本,入侵现实世界:
它能看懂图(VisionTransformer):它把一张图片切成16×16的小方块。在它眼里,这些方块就是“单词”。它能像阅读文章一样,理解图片里的猫在追老鼠。
它能预测生命(AlphaFold):它把蛋白质的氨基酸排列看作是一串代码。它通过计算氨基酸之间的“注意力”,破解了困扰生物学界50年的蛋白质折叠难题,直接助力新药研发。
它不再只是一个翻译官。它是一个超级智能的“文字画家”,也是一个全能的“侦探团队”。
结语:代价与未来
当然,这一切并非没有代价。Transformer是著名的“资源黑洞”。
还记得GPT-3横空出世的那个时刻吗?那是一个“暴力美学”的奇迹。为了训练它,OpenAI投喂了整整45TB的文本数据(这相当于把整个人类互联网的图书馆都搬进了模型里)。
但这就是通往未来的门票。
回顾整个架构:
Encoder负责全知复盘。
Decoder负责即兴演讲。
ResNet&Norm负责深层思考。
Softmax负责给出概率。
作为产品经理,当我们理解了这个“概率机器”的底层逻辑,我们就不会再盲目神话它,也不会低估它。我们正在见证的,不仅仅是一个聊天机器人的诞生,而是人类历史上最通用的推理引擎的崛起。
